About Me!

This blog is about my musings and thoughts. I hope you find it useful, at most, and entertaining, at least.
Other Pages
Presence Elsewhere
What I would like to see as the future of the web
The current HTTP 2 draft is wrongly focused
Tenants of HTTP 0.9, 1.0, and 1.1
HTTP 0.9, 1.0, and 1.1 were built around a set of ideas about how the web should work. Many of these ideas are explained in Chapter 5 of Roy Fielding’s doctoral dissertation, in 2000. Chapter 5, Representational State Transfer, lays out the idea of URLs representing resources and HTTP being used to transfer and represent those resources in a stateless manner. Additionally, HTTP has always been a fairly simple text-based protocol.
Over time, though, the ideas espoused by HTTP and REST have been abused to the point of absurdity. .Net’s ViewState and the multitude of cookies storing kilobytes of data is contrary to the idea of being stateless, not to mention it wastes tons of bandwidth. Roy Fielding had the following to say about cookies:
An example of where an inappropriate extension has been made to the protocol to support features that contradict the desired properties of the generic interface is the introduction of site-wide state information in the form of HTTP cookies. Cookie interaction fails to match REST’s model of application state, often resulting in confusion for the typical browser application. (…) The problem is that a cookie is defined as being attached to any future requests for a given set of resource identifiers, usually encompassing an entire site, rather than being associated with the particular application state (the set of currently rendered representations) on the browser. When the browser’s history functionality (the “Back” button) is subsequently used to back-up to a view prior to that reflected by the cookie, the browser’s application state no longer matches the stored state represented within the cookie. Therefore, the next request sent to the same server will contain a cookie that misrepresents the current application context, leading to confusion on both sides. (…) As a result, cookie-based applications on the Web will never be reliable. The same functionality should have been accomplished via anonymous authentication and true client-side state. A state mechanism that involves preferences can be more efficiently implemented using judicious use of context-setting URI rather than cookies, where judicious means one URI per state rather than an unbounded number of URI due to the embedding of a user-id. Likewise, the use of cookies to identify a user-specific “shopping basket” within a server-side database could be more efficiently implemented by defining the semantics of shopping items within the hypermedia data formats, allowing the user agent to select and store those items within their own client-side shopping basket, complete with a URI to be used for check-out when the client is ready to purchase.
Where HTTP2 strays
We’ve strayed so far from the ideals of HTTP and REST that we’ve come up with protocols such as QUIC and SPDY that do terrible things to accommodate the unholy things being done in the name of “rich web applications.”
The proposed protocols are not simple. “SPDY adds a framing layer for multiplexing multiple, concurrent streams across a single TCP connection (or any reliable transport stream)” (SPDY IETF Draft). I think it’s safe to say that reïmplementing a good portion of TCP inside a Layer 7 protocol is not simple.
Proposed protocols are not text-based. This makes them much more difficult to work with, explore, and debug. I’m terribly tired of people pointing at TLS or SSH and saying it’s binary: Sure, it is, but I’m not working with TLS, it’s a transport protocol and transparent to me. My application consumes, processes and emits arbitrary HTTP. That that text stream is sent through an encrypted stream doesn’t matter to me.
The HTTP 2.0 draft is based heavily on SPDY. This includes a TCP-like protocol inside of it as well as binary header representations. This HTTP 2.0 draft doesn’t carry the HTTP name faithfully. HTTP 2.0 should continue this tradition while fixing problems and simplifying the protocol. This doesn’t mean there isn’t room for a protocol designed for web applications or heavy websites, but it shouldn’t be called HTTP. If it doesn’t sound like a duck or look like a duck, don’t call it a duck.
While I would still prefer a more straight-forward web where images are images, not structural or æsthetic, I see the allure of web apps and acknowledge that a protocol other than HTTP may be better suited for some things, such as WebSockets which uses the HTTP upgrade mechanism and allows for full-duplex socket communication via JavaScript. Even though I find much of the bloat images and JavaScript distracting, I do think that there will be a push away from HTTP to protocols such as SPDY and WebSockets for specific things, and that’s fine. There are ways to specify protocols in URLs and upgrade from within HTTP. However, those protocols are not HTTP and should not be called it or kludged onto the same port.
Why the problems HTTP2 solves aren’t worth solving
HTTP2 is aimed towards making the web faster; towards making heavy websites load more quickly. It aims to reduce the number of back-and-forth requests made. While a good goal, I don’t believe it should be what our time and effort is spent on.
Fast page load speed, while perceived by everyone to be a wonderful thing, isn’t really that big of a deal. People will still use the web, just as they have for 2 decades. It also comes at the expense of attention to issues that should be receiving more attention(in HTTP and HTML):
Ideas that need minds and to be kept in-mind
Better, safer authentication
Currently, there are so many problems with how sites store passwords it’s pathetic. The protocol needs to provide, encourage, and adapt to what is needed for creators to use it, a method that won’t allow such absurd things as storing unhashed or unsalted hashes of passwords.
More secure caching
Currently caches can modify resources as they wish. By allowing, and expecting, signatures these modifications could be verified without requiring TLS.
Better methods to find alternate downloads locations
This is especially usful for large files, such as ISO images and videos. By allowing a method to easily let the user choose other methods to download the file will help lower the load on the server and help encourage a decentralized web.
Making the web more free, as in speech. Make it easier to let people share data.
Allowing support for editable and semantic data formats and allowing standard methods of showing them will encourage content creators to use such formats. Often these formats are much smaller than their rendered counterparts, and can be rendered to be as readable as possible on the device.
Keeping the protocol simple and stateless
Keeping the protocol simple and stateless goes a long way to making it accessible on low-end devices on slow connections. It aids in the cachability of sites, which also aids slow-speed connections.
More-over, being text-based improves the hackability and accessibility of the protocol, which is another tenant that I believe the web should foster.
Keeping web-pages usable by disabled people.
Many people forget about the blind when they build their web page. Web Accessibility is about more than just blind folk, but also those with motor impairment and the deaf. §508 in the US has laws relating to government web pages, but the techniques and advice apply equally to all pages.WAI — Web Accessibility Initiative from the W3C has useful information and tips as well. WebAIM — Web Accessibility In Mind also has helpful information.
While this is more of a problem with design, but the protocols and markup we use should keep this in mind as well. For videos, for instance, there should be a way to have captions available outside of the video stream. There are proposals for this (and there is a JavaScript module that supports this, VideoJS), but it should be standard, not a hack.
Making each request contain less information about the sender
By reducing the attack surface, it becomes more difficult to identify a specific UA. panopticlick from the EFF shows just how much data is leaked by our browsers when we visit a site. (Without JavaScript I sent the equivalent of 13bits of identifying info, 10bits from the UA. JavaScript brought that value to 22bits.) There is no reason to be leaking this information to sites we visit.
There are other issues that need minds, but aren’t under the umbrella of HTTP or HTML:
Distributed Authentication of Public Keys and TLS Keys, i.e. a Distributed PKI not based on CAs
CAs have been compromised, hijacked, or forged in the past and will in the future. A workable, decentralized system to authenticate keys is perhaps the only way to truly solve this problem. Pinning is defiantly a good thing, but it can only help so much, especially with valid certificates.
Making distributed systems and searching more convenient and common
Systems like I2P (wiki), GNUNet (wiki), and FreeNet (wiki) are systems that allow distributed file storage, web sites, and messaging. Making these systems easier to use and more integrated with the “normal” internet. More research may be needed on these system to identify problems and flaws in them.
Tor (wiki) is an anonymity network that has been the subject of many academic papers. Being able to transparently use Tor always, or during Private Browsing, would be an awesome win.
Updates to HTTP 1.1
Dates
Removal of the Date Header
I have yet to see a convincing argument for it. Perhaps only making it required for POSTs, PUTs, and DELETEs and making it optional on GETs would be a good option as well. However, since there is no guarantee that any clocks are synchronized, date stamping is tedious at best and useless at most. At least an If-Modified-Since uses a date given by server (should could be set via a Last-Modified header). Not sending this header also removes certain types of tracking attacks.
Formats
Dates can be in ISO 8601 (e.g.: 2013-07-09T08:13:10Z) instead of RFC 1123 (e.g.: Mon, 09 Jul 2013 08:13:10 UTC) as I don’t understand what the RFC 1123 format brings to the table that the ISO 8601 doesn’t.
Proxies
X-Forwarded-For and X-Forwarded-Proto should be promoted to standard (without the X- prefix, obviously) and their formats formalized. The de facto standard of a comma separated list for X-Forwarded-For and a simple string and not a list (e.g.: http or https) for X-Forwarded-Proto should suffice. For the X-Forwarded-Proto, however, if the value is a not encrypted protocol (e.g.: http) the value should never be changed to an encrypted on (e.g.: https) and should be set by each proxy if setting X-Forwarded-For. The only time it should be valid to downgrade or otherwise set the X-Forwarded-Proto would be in an internal network (e.g.: using Stud or STunnel to forward to HAProxy to load-balance for a set of servers. In this situation, HAProxy downgrading the proto would be useless and counter-productive).
Signing and Digests
Content-Signature with the signing key being the TLS/SSL key. This could aid in secure caching, mirroring, and proxying. This will help ensure that proxies and mirrors are serving up a trustworthy copy of the resource.
Whatever standard is used for the Content-Signature header, there should be a way to link to the signing key, so that it can be downloaded. This still has the problem of being able to verify that the key being downloaded actually belongs to the claimed signer. I don’t think that this is a problem that could be solved in a post about updating HTTP. Regardless, the standard should have a standard way of giving this basic information.
Deprecate Content-MD5 in favour of a Content-Hash header whose value would be a space delimited “algo hash”. I feel that this is a more future-proof and flexible header. This header could be specified multiple times, each with a different algorithm. However, it also opens the chance that a server could give a client a hash algorithm that it is unfamiliar with and hence can’t use. I would suggest that hash algorithms of md5, sha1, sha224, sha256, sha384, sha512, and whirlpool (or perhaps only sha512?) be standardly supported and that if a server decides to send a function not on this list, it should additionally send one from the list as well.
The encoding of the hash could be hex, base32, or base64 which are fairly well-known standards. I, however, prefer base58 because I like some of the reasonings found in the header for it in the bitcoin project.
// Why base-58 instead of standard base-64 encoding?
// – Don’t want 0OIl [ed. note: zero, oh, capital i, lowercase ell] characters that look the same in some fonts and
// could be used to create visually identical looking account numbers.
// – A string with non-alphanumeric characters is not as easily accepted as an account number.
// – E-mail usually won’t line-break if there’s no punctuation to break at.
// – Doubleclicking selects the whole number as one word if it’s all alphanumeric.
Specifically, not using characters that would be reserved in URLs and not using characters that aren’t visually identical or similar in many fonts. Both of these can (and will) aid debugging for those cases in which the hash must be read and interacted with by a human.
Deprecate Etag in favour of If-[Not-]Hash and Content-Hash tag. If-[Not-]Hash would use the same semantics as the Content-Hash tag. In theory, this should prevent some of the tracking attacks that ETags are subject to if the hash is only used if it can be verified by the User Agent. One downside, however, is that some ETag implementations are done in a way such that the contents of the file don’t need to be read (e.g.: Apache). The internal representation could be used in a dictionary as the key to the hash, so it may not be a terrible change or overhead.
Alternate Download methods
Magnet would contain a magnet link for the file. In theory, most of the information here could be present in the Content-Hash header. I could see this being used in conjunction with the Content-Range header to give information on how to use BitTorrent to download the remainder of a file, say a CD or DVD image. Some browsers, namely Opera, already have clients that would support BitTorrent and could support this type of header with minimal retooling. If the client would like to download the entire file, it can resubmit the request with a Range header for the rest of the file. The Server could respond with the rest of the file or a redirect to a mirror.
Mirror would contain the URL of a mirror of the resource. This header could be repeated multiple times in order to specify multiple mirrors. In a similar manner to the Magnet header, if the server would prefer the User Agent use mirrors, then it could respond with a Content-Range header so that it doesn’t have to deliver the entire resource.
Additional Metadata
In the spirit of the HTTP headers containing metadata about the resource, I would propose some additional headers to convey useful and broadly-used metadata. These headers are especially useful for formats that don’t contain their own metadata (i.e.: textile, markdown, images).
Copyright-Holderwould contain the address of the resource owner. This should be RFC 2822 format (me@example.com or Me Meener <me@example.com>. If the value is not RFC 2822 complaint, the value will be treated as a literal. TheAuthorheader may be used if this header is not present.Copyright-Yearwould contain the year the work was copyrighted. If not present, theLast-Modifiedheader may be used as theCopyright-Year.Copyright-License-Namewould contain a human readable name for the license, e.g.: CC-BY-SA-3.0 License, BSD License, MIT License, GNU FDL-1.3, GPL-3.0 (corresponding to the links in the next section). The name could also be “All Rights Reserved.”Copyright-License-Text-URLwould contain a link to a resource that contains copyright information for the requested resource(e.g.: https://creativecommons.org/licenses/by-sa/3.0/, http://opensource.org/licenses/BSD-2-Clause, http://opensource.org/licenses/MIT, https://www.gnu.org/licenses/fdl-1.3.txt, or https://www.gnu.org/licenses/gpl-3.0.txt). The link could also point to a local copy of the license or a file that contains only “All Rights Reserved” or be “data:text/plain,All Rights Reserved.”Descriptionwould contain a summary or caption text for a resource. I would propose to limit the value to 255 characters. The value could be used foraltattributes for images if one is not given.Titlewould contain the title of the resource. I would propose a 255 character limit. The value could be used foraltattributes for images if no other source is given.Authorwould contain the author in RFC 2822 format (or failing that, the value is treated as a literal).- Encourage use of the Link Header.
- In the same vain as the
Linkheader, aMetaheader where the value would be key=value, e.g.: Meta: geo.country=US
For instance, the headers for http://jimkeener.com/img/me2.jpg (my profile image to the left) could be:
{kind=link}
HTTP/1.1 200 OK
Last-Modified: 2012-07-22T00:00:00Z
Content-Type: image/jpeg
Content-Length: 77898
Content-Hash: sha1 859304ca94b0cac1092fa860103c4b370ba08821
Copyright-Year: 2012
Copyright-Holder: Jessica M <jessie.m@example.com>
Copyright-License-Name: All Rights Reserved
Copyright-License-URL: data:text/plain,All Rights Reserved
Description: And completely ridiculous. Taken after the Keener wedding.
Better Authentication
Mutual Authentication and actually encouraging people to use it. I understand that websites want a cohesive environment, but for security and architectural reasons, using a standard authentication mechanisms will save everyone a lot of headache. Not to mention remove the storage of plain-text passwords.
Also, encouraging people to use TLS-SRP would be a good step as well. TLS-SRP and client certificates could provide a means of 2-factor authentication.
Removal of Useless headers
Like the Date header I’ve mentioned earlier, I feel that there are headers that server little to no purpose, and in some cases actually hurt the idea behind the web.
The User-Agent header, while it’s nice for analytics, serves no real purpose and is harmful by allowing User Agent sniffing. The application shouldn’t care about the User Agent being used. Removing this header also decreases the amount of information available to identify the user.
Perhaps a nice compromise would be for UAs to send minimal User-Agent headers. For instances,
| instead of | Possible UA |
|---|---|
| Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727) | Windows NT 5.1/MSIE 6.0 |
| Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36 | Windows NT 6.1/Chrome/28.0 |
| “Mozilla/5.0 (iPhone; CPU iPhone OS 6_1_3 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Mobile/10B329 | iOS 6.1.3/AppleWebKit/536/26 |
| Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:23.0) Gecko/20100101 Firefox/23.0 | Ubuntu Linux/Firefox/23.0 |
All UAs would be free to include whatever they want, but I feel “OS/UA” is a nice, short compromise. It doesn’t leak as much information, but can also provide information for analytics. Additionally bots would continue to be encouraged to include links to their info pages or email address in their UA strings.
Similarly, the Server header provides no real value and is just bytes being sent that are just ignored on the other end. It shouldn’t matter what server you’re talking to.
I’m still trying to find a good use for the Via header. Especially if User-Agent is removed, I’m not aware of why the need for a list of the proxy UAs is necessary
I am also trying to figure out a good use of Pragma and am debating if allowing implementation specific standard headers is a good idea. An implementation is always free to use the X- prefix for a header, making it clear that what is happening is non-standard.
DNT header is, in my opinion, worthless and should just be dropped. If I make a request to a site, I expect that that request is going to be logged indefinitely. If I don’t want to make that request, I choose not to (NoScript, Ad Block Plus, and Ghostery go a long way towards this). It’s quite useless and does nothing of any value and is entirely unenforcible. Worse it gives a feeling of security without actually doing anything.
P3P should just be dropped. If I make a request to a site, I expect that that request is going to be logged indefinitely. The P3P policies are also entirely informational and don’t relate to the resource being returned. Even those who designed it called it a waste of time. It’s quite useless and does nothing of any value and is entirely unenforcible. Worse it gives a feeling of security without actually doing anything.
(Yes, I know the last two aren’t part of the core HTTP standard, but I felt like mentioning them as they are just useless.)
I’m also still trying to fully understand CORS. It seems like it requires a trustworthy server and client for it to work. Both of these seem like bad assumptions. Perhaps I’m missing the point, but I’m still trying to understand the situations in which it is the best option.
Sessions
Removal of the Cookie and Set-Cookie headers. Cookies are a kludge on top of a resource retrieval protocol. HTTP Authentication, WebSQL, and LocalStorage should take care of any cross-requests state.
Simplicity
Single line headers, i.e. no line continuations. I’d prefer a max-size, but it would have to be over 2kb because of the Referer header. I’ve toyed with the idea of removing the Referer header, but it is useful for analytics and debugging (finding the source of bad links).
I would also be in favour of removing HTTP Keep Alive as it seems to be misplaced and just adds complexity. Willy Tarreau gives a good explanation about some of the pros and cons of Keep-Alive in this StackOverflow thread and on the HAProxy page. From the HAProxy “Design Choices and History”:
Keep-alive was invented to reduce CPU usage on servers when CPUs were 100 times slower. But what is not said is that persistent connections consume a lot of memory while not being usable by anybody except the client who openned them. Today in 2009, CPUs are very cheap and memory is still limited to a few gigabytes by the architecture or the price. If a site needs keep-alive, there is a real problem. Highly loaded sites often disable keep-alive to support the maximum number of simultaneous clients. The real downside of not having keep-alive is a slightly increased latency to fetch objects. Browsers double the number of concurrent connections on non-keepalive sites to compensate for this. With version 1.4, keep-alive with the client was introduced. It resulted in lower access times to load pages composed of many objects, without the cost of maintaining an idle connection to the server. It is a good trade-off. 1.5 will bring keep-alive to the server, but it will probably make sense only with static servers.
While I understand the usefulness of Keep-Alive, I just can’t help but feel it complicates things and doesn’t belong as part of HTTP. I feel like this should be at the TCP level, where there should be some way to reïnitalize a connection, the RST flag seems to abort a connection, which would be the opposite of what I’m looking for. This proposed behavior would be similar to the PSH flag where it would push data to the application, and then behave as-if the connection had been newly established. In the context of a web server, this would cause the server to act is if a new connection with the same source port-ip/destination port-ip as before. It would not have any relationship to the previous requests.
User Agent changes
Some of these may be more suited as plugs ins, while others would be better suited in the core rendering libraries. All, however, I feel will enhance the dispersal of information.
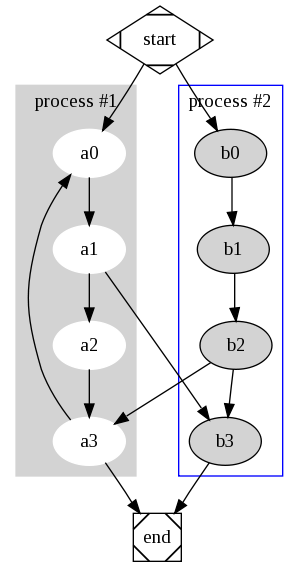
DOT
DOT (used by GraphViz) support in <img> tags. A MIME Type of text/vnd.graphvis could be used. It would be nice if the DOT commands could be placed inside <img type=“text/vnd.graphvis”> and </img> tags. I would imagine taking advantage of SVG support and having the browser compile the file to SVG for display and styling. (Example taken from GraphViz site). I could imagine JavaScript libraries appearing to allow interaction with the graphs.
Along these lines, but more generally, the D3 library seems to provide many niceties as well.
digraph G {
subgraph cluster_0 {
style=filled;
color=lightgrey;
node [style=filled,color=white];
a0 -> a1 -> a2 -> a3;
label = “process #1”;
}
subgraph cluster_1 {
node [style=filled];
b0 -> b1 -> b2 -> b3;
label = “process #2”;
color=blue
}
start -> a0;
start -> b0;
a1 -> b3;
b2 -> a3;
a3 -> a0;
a3 -> end;
b3 -> end;
start [shape=Mdiamond];
end [shape=Msquare];
}
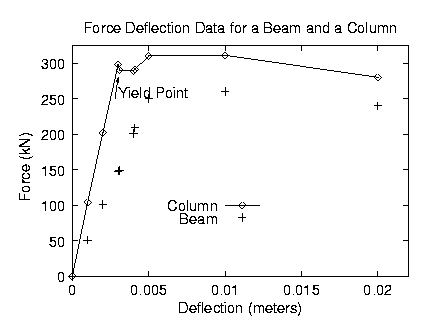
GNU Plot
GNU Plot support in <img> tags. A MIME Type of application/gnuplot could be used. I could also see “text/vnd.gnuplot” used and believe it makes more sense. It would be nice if the GNU Plot commands could be placed inside <img type=“text/vnd.gnuplot”> and </img> tags. I would imagine taking advantage of SVG support and having the browser compile the file to SVG for display and styling. (Example taken from hpgavin’s Duke site) (force.dat would be in the same directory. /force.dat would be in web root, using the same semantics as all other tags.) While it would be nice for User Agents to allow zooming on graphs, I would expect JavaScript libraries to appear to manipulate and interact with the plots.
# Gnuplot script file for plotting data in file “force.dat“
- This file is called force.p
set autoscale # scale axes automatically
unset log # remove any log-scaling
unset label # remove any previous labels
set xtic auto # set xtics automatically
set ytic auto # set ytics automatically
set title “Force Deflection Data for a Beam and a Column”
set xlabel “Deflection (meters)”
set ylabel “Force (kN)”
set key 0.01,100
set label “Yield Point” at 0.003,260
set arrow from 0.0028,250 to 0.003,280
set xr [0.0:0.022]
set yr [0:325]
plot “force.dat” using 1:2 title ‘Column’ with linespoints , \ “force.dat” using 1:3 title ‘Beam’ with points
Barcodes
<barcode> tag support. As a fallback, perhaps nesting a barcode tag inside an image tag (e.g.: <img src=“Hello-qr.jpg”><barcode type=“qr” mode = “h”>Hello</barcode></img>) until more browsers support it. I believe that this could be a useful tag because it seems very wasteful to send an image when a small amount of text could do. I would imagine taking advantage of SVG support and having the browser compile the file to SVG for display and styling. As a side note, there is a JavaScript barcode renderer, bwip-js which could be used as the basis for a plugin.
<barcode type=“qr” mode=“H”>Hello</barcode>

Markdown
<div format=“format” rules=“rules”> where format would be latex (or some specific subset of it), markdown, textile, asciidoc, troff / nroff (used for man pages), or restructuredtext. Rules would be a comma separated list of nolinks, noimages, and/or nocss. This would be useful for user-generated content as it would prevent many XSS attacks (since it could refuse to execute JavaScript in these divs), and the rules would allow additional control over the rendering. This is just an idea and I’m not 100% sure how useful it would be. Also, this could apply to a document in-and-off itself and not inside of an HTML div.
<div format=“textile” rules=“nocss,noimages”>
Search results for **Textile**:h4. ["**Textile** (markup language) – Wikipedia":http://en.wikipedia.org/wiki/Textile_(markup_language)]
**Textile** is a lightweight markup language originally developed by Dean Allen and billed as a "humane Web text generator". **Textile** converts its marked-up text ...
</div>
Search results for Textile:
Textile (markup language) – Wikipedia
Textile is a lightweight markup language originally developed by Dean Allen and billed as a “humane Web text generator”. Textile converts its marked-up text …
Citations
A better system for citations, perhaps with bibliography data in bibtex format (for compatibility). I wouldn’t be opposed to porting bibtex into a more HTML/XML-like syntax. There could be a corresponding <citebib> or <ref> tag that would include a reference and link to citation, similar to how Wikipedia <ref> works. The following example is a proposed method of doing this. The example is based on BibTeXML’s Examples I also imagine CSS changes to control the citation type, both inline and the generated full citation.
<style>
body { bibliography-inline: ACM; bibliography: Harvard;
}
</style><p>This <ref ref-id=“berkman”></p>
<p>Is <ref ref-id=“robinson”></p>
<p>Test <ref ref-id=“huffman”></p><h1>Bibliography</h1>
<!— bibliography may have a src element —>
<bibliography>
<bibtex:file xmlns:bibtex=“http://bibtexml.sf.net/”><bibtex:entry id=“berkman”> <bibtex:book> <bibtex:author>Berkman, R. I.</bibtex:author> <bibtex:title> <bibtex:title>Find It Fast</bibtex:title> <bibtex:subtitle>How to Uncover Expert Information on Any Subject</bibtex:subtitle> </bibtex:title> <bibtex:publisher>HarperPerennial</bibtex:publisher> <bibtex:year>1994</bibtex:year> <bibtex:address>New York</bibtex:address> </bibtex:book>
</bibtex:entry><bibtex:entry id=“robinson”> <bibtex:book> <bibtex:editor> <bibtex:person>Robinson, W. F.</bibtex:person> <bibtex:person>Huxtable, C. R. R.</bibtex:person> </bibtex:editor> <bibtex:title>Clinicopathologic Principles For Veterinary Medicine</bibtex:title> <bibtex:publisher>Cambridge University Press</bibtex:publisher> <bibtex:year>1988</bibtex:year> <bibtex:address>Cambridge</bibtex:address> </bibtex:book>
</bibtex:entry><bibtex:entry id=“huffman”> <bibtex:article> <bibtex:author>Huffman, L. M.</bibtex:author> <bibtex:title>Processing whey protein for use as a food ingredient</bibtex:title> <bibtex:journal>Food Technology</bibtex:journal> <bibtex:year>1996</bibtex:year> <bibtex:volume>50</bibtex:volume> <bibtex:number>2</bibtex:number> <bibtex:pages>49-52</bibtex:pages> </bibtex:article>
</bibtex:entry></bibtex:file>
</bibliography>
<p>This [<a href=”#bibliography-berkman”>Berkman 1994</a>]</p>
<p>Is [<a href=”#bibliography-robinson”>Robinson 1988</a>]</p>
<p>Test [<a href=”#bibliography-huffman”>Huffman 1996</a>]</p><h1>Bibliography</h1>
<p><a name=“bibliography-berkman”>Berkman, R. I. 1994. <em>Find It Fast: How to Uncover Expert Information on Any Subject</em>, HarperPerennial, New York.</a></p><p><a name=“bibliography-robinson”>Robinson, W. F. & Huxtable, C. R. R. (eds) 1988. <em>Clinicopathologic Principles For Veterinary Medicine</em>, Cambridge University Press, Cambridge.</a></p>
<p><a name=“huffman”>Huffman, L. M. 1996. ‘Processing whey protein for use as a food ingredient’ in <em>Food Technology</em>, vol.50, no.2, pp.49-52.</a></p>
STS
Strict-Transport-Security wouldn’t be required because TLS would always be used. Self-signed certificates would be treated as unencrypted traffic is now (e.g.: no indication in the address bar like current TLS indications give). However, User Agents should attempt to pin known certificates and having certificates signed by the previous certificate would also increase assurance of having a valid certificate. I don’t feel that requiring TLS is the job of HTTP, though. The browser should first try to access a site via TLS before attempting a unencrypted connection.
hash attribute
On tags with a src or href attributes, an alternative hash attribute (with the same semantics as the Content-Hash header) should be added to aid in caching and to not have to round trip to the server to see if the file has been updated. This attribute could also be used to allow the specification of alternative sources via multiple src attributes. The order to check is the order in the tag.
<script src="//ajax.googleapis.com/ajax/libs/jquery/1.10.2/jquery.min.js" src="/js/jquery-1.10.2.min.js" hash="sha1 e2f3603e23711f6446f278a411d905623d65201e"></script>
Another option would be be the source tags, similar to in the HTML5 Spec
<script hash = "sha1 e2f3603e23711f6446f278a411d905623d65201e"> <source src="//ajax.googleapis.com/ajax/libs/jquery/1.10.2/jquery.min.js" type="text/javascript"> <source src="/js/jquery-1.10.2.min.js" type="text/javascript"> </script>
Fragment—h-tag correlation
The text in a header tag (e.g.: <h1></h1>) could be used in URL fragments. For instances <h2>Things I like</h2> could be accessed by http://example.com/page#Things+I+like.
CSS Updates
Native LESS or SASS support. SASS would be my preference, but either would do. Ideally the CSS standard would support many of the features offered by these languages, but I don’t think that’ll happen anytime soon. I would suggest that these be differentiated by MIME types such as text/css+x-less and text/css+x-sass for use in style tags, e.g.: <style src=“custom.scss” type=“text/css+x-sass”></style> (Yes, I also think <style> should have a src attribute.)
Obviously LESS has JavaScriprt renders. There are also efforts to have JS SASS parsers as well.
Table-of-Contents Generation
A toc-tag that would auto-generate a table-of-contents. Some consideration would be required to make this easily style-able via CSS. Simply placing classes in each tag may be easy, but runs the risk of collisions. Prefixed classes may decrease this chance, for instance “toc-h1” as a class. There are numerous JavaScript libraries, such as generate_toc, that do something very similar.
<h1>Table of Contents</h1>
<toc><h1>Test</h1>
<h2>Idea</h2>
<h1>Table of Contents</h1>
<div class=“toc-body”>
<a href=”#Table-of-Contents” class=“toc-h1”>Table of Contents</a>
<a href=”#Test” class=“toc-h1”>Test</a>
<a style = “padding-left: 10px” class=“toc-h2” href=”#Idea”>Idea</a>
</div>
<h1>Test</h1>
<h2>Idea</h2>
Auto Section numbering
It would be nice to, via CSS, specify that h-tags should be numbered, with the same list-style-type options as a ol-tag.
CSS is capable of having a counter and then displaying a number (but only a number). This requires support for the counter-increment, counter-reset, as well as content-before. See Automatically numbering headings via CSS for more information on how to do this.
HTTP methods in form-tags
Support for PUT and DELETE as method attribute values in forms.
Better JavaScript Crytpo
window.crypto standardized and supported among more browsers. I would also like to see the API of from Node.js’ crypto module merged into it, as it provides many nice primitives and hashing capabilities.
Native CSV support
Similar to how it is becoming more common to render PDFs in the web-browser, having an option to display it in a (read-only) spreadsheet that can be sorted, searched, and queried.
XMLHTTPRequests require user acceptance
JavaScript shouldn’t, without user input, be able to make AJAX requests. In theory the browser can pause execution of the script while it waits for user input, like what happens with an alert() box.
I would prefer options of: “OK, for this page, while I’m on it”, “OK, for this domain, while I’m on it”, “OK for this page, forever”, “OK, for this domain, forever”, “No”. This way, while you’re on a page the javascript won’t ask constantly, but it provides some granularity of what’s allowed and when.
MathML Support and/or inline LaTeX support
I would love more wide-spread support for MathML or <span format=“tex”>. This is related to the markdown suggestion above, but only for inline equations.
I feel that good math support is an ideal for the exchange of information. Without good formatting we rely on plugins, javascript, or hacks (which is a strong word. The people who make libraries like LaTexMathML and MathJax are extremly talented, but I feel that the rendering should be done by the UA, not JS code). MathML is already supported in some browsers and standardized already and I see no good reason that it shouldn’t be on the goal list for all browsers.
The left column is MathML, the middle is Tex, the last is how I would like it to be rendered (as an image, and then with MathML, if your browser supports it).
<math> <mrow> <msqrt> <msup> <mtext>x</mtext> <mn>2</mn> </msup> <mtext> </mtext> <mo>+</mo> <mtext> </mtext> <msup> <mtext>y</mtext> <mn>2</mn> </msup> </msqrt> <mtext> </mtext> <mo>=</mo> <mtext> r</mtext> </mrow>
</math>
<span format=“tex”>\sqrt{x^2 + y^2} = r</span>
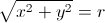
Revision Histories and Comments
Similar to how MS Word and LibreOffice Writer can track changes in a document and allow comments to be made on the text, a system for tracking changes in a text-based system would be ideal for people collaborating on a single document.
I would propose <ins> and <del> for insertions and deletion edits. Since edits are temporally ordered, I would propose that these two tags have at attributes that would accept ISO 8601 (e.g.: 2013-08-16T19:35:00EST).
Additionally, there would be an by attribute that would be the name of the author. It is recommended that this be in RFC 2822 format, but otherwise it could be treated as a literal.
I would also feel that a rev attribute could be useful. This would contain the current revision ID is (e.g.: “86c1056” or “86c105638449bb87dde7815bb69260d167249d37” for git or “42” for svn).
Beyond inserts and deletions, <comment>, with the same attributes as above, would contain the text of a comment to be shown at the current location.
Now, the <ins> and <del> are already standard and render as an underline and strike-through, respectively. I am also proposing a repurposing of the defunct and all-but-unused <comment> tag. My proposal adds and author and timestamp to those tags to make it possible to nest revisions, which would allow the rendering of any specific version (defaulting to the most current) by the User Agent (which could provide some mechanism to view previous version).
One might ask why a proper SCM system couldn’t be used. The answer is mainly social and about the existing tools. Socially, people still email documents back and forth. As such, a git repository wouldn’t be a good choice. Tool-wise, LibreOffice, for instance, could support this in its HTML import and export abilities, especially since it already supposes these basic functions (ins, del, comment) in its support for Word.
Perhaps, for the purpose of clarity, the tags could be name-spaced so that they don’t conflict with the existing tags, e.g.: <rev:ins>, <rev:del>, <rev:comment>.
For instance, the following markup could be rendered as:
This <del by=“user@jimkeener.com” at=“2013-08-16T19:35:00EST”>is</del><ins by=“user@jimkeener.com” at=“2013-08-16T19:35:00EST”>will be</ins> a standard<comment by=“user@jimkeener.com” at=“2013-08-16T19:35:00EST”>Maybe a clear RFC can be created?</comment>!
Or, like how comments are rendered in word-processors, the comment could appear in the side margin.
Better Justified text
The option to us the Knuth-Plass line break algorithm to do justified text. There is a JavaScript implementation of the Knuth-Plass algoithm.
I would like to see, at least CSS text-align support for “kp-justified”, but it could also support “kp-left”, “kp-right”, “kp-center”. This would provide much better typography and ease of reading on the web.